Services Australia tested the BigDataStack used OpenShift on OpenStack with Kuryr software.
RedHat customer Services Australia tested OpenShift on OpenStack with Kuryr software, as used in BigDataStack. Services Australia is responsible for the delivery of advice and high-quality, accessible social, health and child support services and payments.
“Services Australia was interested in utilising the benefits of running OpenShift on OpenStack with Kuryr. Primarily by allocating floating IPs to OpenShift services, thus facilitating inter-cluster communication, in addition to the performance enhancements that come with avoiding double encapsulation.” Services Australia

Dimensioning data-intensive applications with BigDataStack
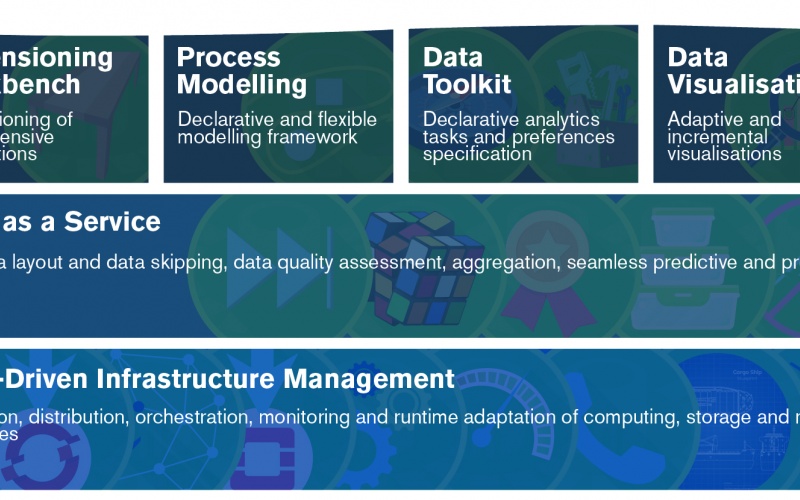
In this series, BigDataStack is taking each of its six services under the looking glass, highlighting its software components, their functionalities and place in the BigDataStack infrastructure management. Each service consists of a set of software components that allow for specific Big Data applications and operations, that will be showcased. For you, to have a quick understanding of the added value of the BigDataStack software for your own business, BigDataStack partners have prepared a series of videos. Now we look at the Dimensioning Workbench for the dimensioning of data-intensive applications.

BigDataStack - the full architecture
Finally out the ultimate version of the BigDataStack architecture following the previous releases describing our “Conceptual model and Reference architecture” (namely D2.4 and D2.5).
BigDataStack Declarative and Flexible Modelling Framework
In this series, BigDataStack is taking each of its six services under the looking glass, highlighting its software components, their functionalities and place in the BigDataStack infrastructure management. Each service consists of a set of software components that allow for specific Big Data applications and operations, that will be showcased. For you, to have a quick understanding of the added value of the BigDataStack software for your own business, BigDataStack partners have prepared a series of videos. Now we look at the Process Modelling a Declarative and Flexible Modelling Framework

Reaping the benefits of BigData developments: Big Data Pilot Demo Days
During the virtual BDV PPP Summit 2020 BigDataStack, I-BiDaaS, Track & Know and Policy Cloud joined forces in a series of 9 online demonstrations of innovative Big Data Technologies unlocking the potential of applications in domains spanning from telecommunications, transport, finance, retail, manufacturing 4.0 and health to citizen mobility and policy-making against radicalisation.

Data Skipping technology ported to Apache Spark 3.0
The Apache Spark community announced the release of Spark 3.0 on June 18 and is the first major release of the 3.x series. The release contains many new features and improvements. IBM ported Data Skipping Technology to Apache Spark 3.0, by contributing comments to the Open Source Community.

Insights from the Big Data Pilot Demo Day - A BigDataStack Seafarer’s Tale Of Real-Time Shipping
Hosted by BDV PPP. BigDataStack, I-BiDaaS, Track & Know and Policy Cloud join forces in a series of online demonstrations of innovative Big Data Technologies unlocking the potential of various applications.

Big Data Pilot Demo - BigDataStack Connected Consumer
BigDataStack will provide retailers with optimal insights into consumer preferences and increase the effectiveness of marketing strategies to improve consumer shopping experience.

BigDataStack Data Toolkit for easy ingestion of data analytics functions
The BigDataStack Data Toolkit aims at openness, extensibility and wide adoption. The toolkit allows the ingestion of data analytics functions and the definition of analytics in a declarative way. It allows data scientists and administrators to specify requirements and preferences both for the data, the analytic functions parameters and infrastructure management. This BigDataStack service is composed of the Data Toolkit and Process Mapping software components, and visualised through the Data Visualisation technologies to improve its usability.

FinTech and InsuranceTech case studies digitally transforming Europe’s future with BigData and AI-driven innovation
The new data-driven industrial revolution highlights the need for big data technologies to unlock the potential in various application domains. The insurance and finance services industry are rapidly transformed by data-intensive operations and applications. FinTech and InsuranceTech combine very large datasets from legacy banking systems with other data sources such as financial markets data, regulatory datasets, real-time retail transactions and more, improving financial services and activities for customers.
