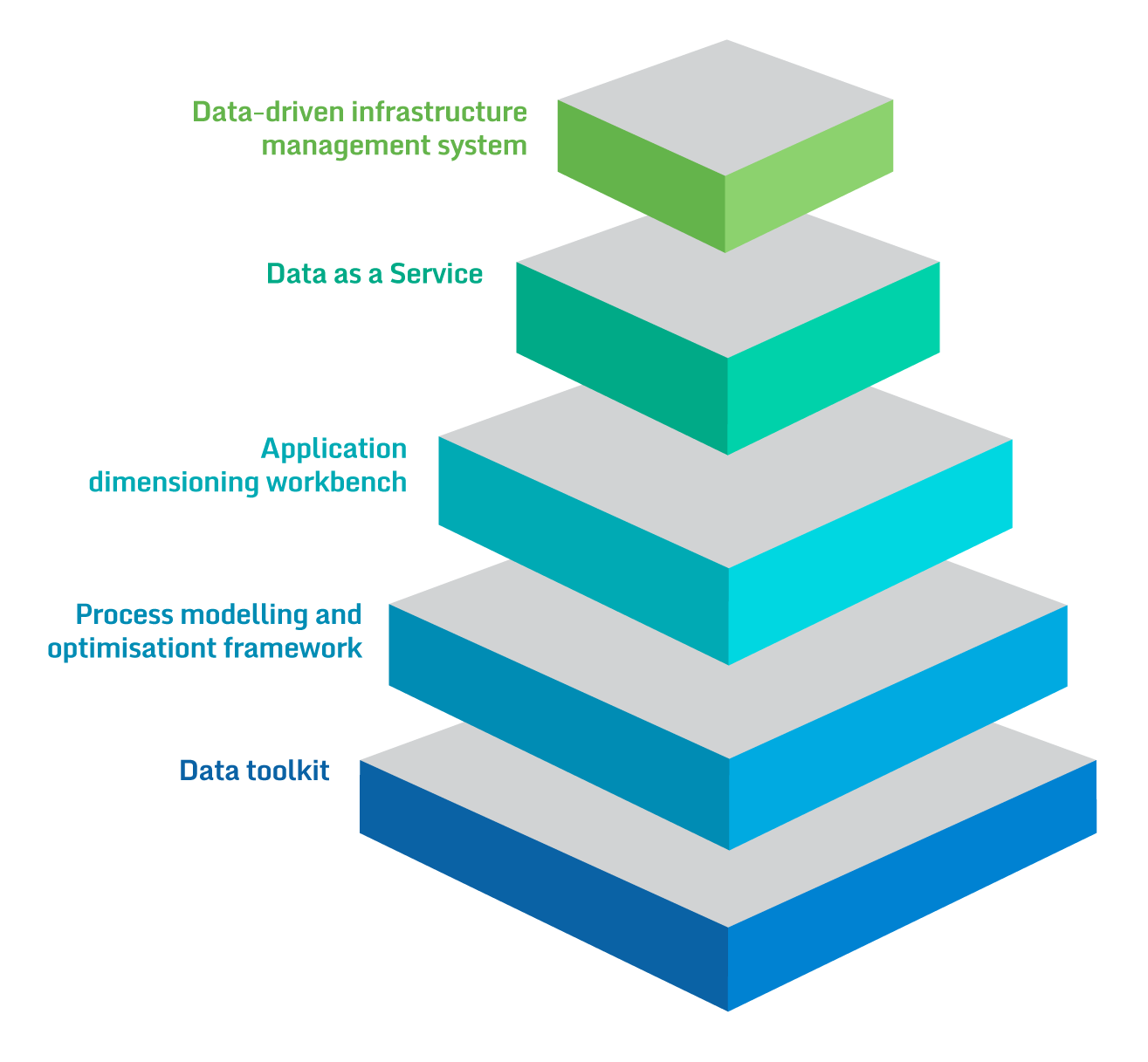
BigDataStack introduces the paradigm of a new frontrunner data-driven system ensuring that computing, storage and networking resources management will be fully efficient and optimized for data operations and data-intensive applications.
The system will base all infrastructure management decisions on the data aspects and the data operations governing and affecting the interdependencies between storage, compute and network resources.
Data as a Service promotes automation and quality and ensures that the provided data are meaningful, of value and fit-for-purpose through approaches for data cleaning, modelling, interoperability, and efficient storage.
Unique seamless data analytics will be realized in a holistic fashion across multiple data stores and locations, along with advanced modelling techniques defining flexible schemas that can be exploited across processing frameworks.
The workbench facilitates data-focused application analysis and dimensioning in terms of predicting the required data services, their interdependencies with the application micro-services and the required underlying resources.
Allowing the identification of the applications data-related properties and their data needs, it enables the provision of specific performance and quality guarantees.
Framework allowing the flexible, functionality-based modelling of processes, which will be mapped in an automated way to concrete technical-level process mining analytics.
The analytics outcomes will be providing feedback to the business analysts with specific recommendations towards overall process optimization and adaptation.
Data toolkit enabling open and extensibility by providing an environment to data scientists and practitioners to easily ingest their data analytics functions by utilizing a declarative paradigm, as well as to specify their preferences and constraints that will be exploited by the infrastructure management system for resources and data management accordingly.
