The BigDataStack Solution
The BigDataStack Software Component Catalog
BigDataStack aims at providing a complete infrastructure management system, which will base the management and deployment decisions on data from current and past application and infrastructure deployments. This complete infrastructure management system is delivered as a full“stack” that facilitates the needs of operation data and application.
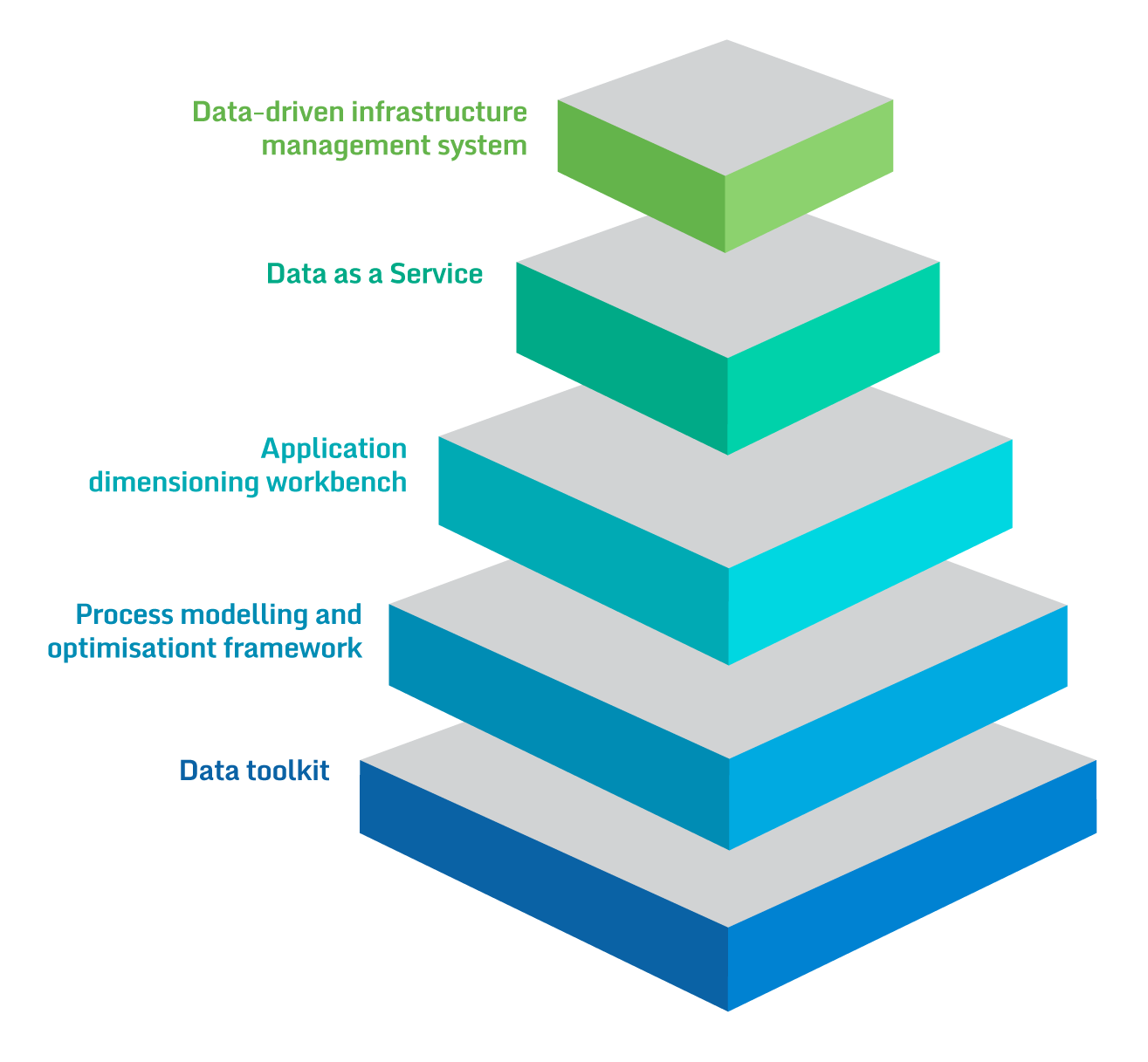
BigDataStack introduces the paradigm of a new frontrunner data-driven system ensuring that computing, storage and networking resources management will be fully efficient and optimized for data operations and data-intensive applications.
The system will base all infrastructure management decisions on the data aspects and the data operations governing and affecting the interdependencies between storage, compute and network resources.
Data as a Service promotes automation and quality and ensures that the provided data are meaningful, of value and fit-for-purpose through approaches for data cleaning, modelling, interoperability, and efficient storage.
Unique seamless data analytics will be realized in a holistic fashion across multiple data stores and locations, along with advanced modelling techniques defining flexible schemas that can be exploited across processing frameworks.
The workbench facilitates data-focused application analysis and dimensioning in terms of predicting the required data services, their interdependencies with the application micro-services and the required underlying resources.
Allowing the identification of the applications data-related properties and their data needs, it enables the provision of specific performance and quality guarantees.
Framework allowing the flexible, functionality-based modelling of processes, which will be mapped in an automated way to concrete technical-level process mining analytics.
The analytics outcomes will be providing feedback to the business analysts with specific recommendations towards overall process optimization and adaptation.
Data toolkit enabling open and extensibility by providing an environment to data scientists and practitioners to easily ingest their data analytics functions by utilizing a declarative paradigm, as well as to specify their preferences and constraints that will be exploited by the infrastructure management system for resources and data management accordingly.
In its turn, each block is made up of a cluster of software components. Below you can find the technical description, Licenses analysis, main competitors in the field and the open software codes listed on GitHub and GitLab.
Data-driven Infrastructure Management

Realization Engine
(Previously, Deployment Recommendation Service) The component enables the production, deployment, and management of cloud deployment configurations. It enables to manage end-to-end the process of producing and monitoring optimal deployment configurations
Factsheet
Code
Apache License 2.0

NVME-mdev Kernel driver
NVMe-mdev kernel driver to have fast storage virtualization.
Factsheet
Code
Apache License 2.0

OVN-Load-Balancer
Integration of ovn load-balancer through its octavia driver into Kuryr for E/W traffic.
Factsheet
Code
Apache License 2.0

Infrastructure API
Unified API for infrastructure resources to make infrastructure management easy and abstracted from the real infrastructure.
Factsheet
Code
Apache License 2.0https://youtu.be/pXOcJMRHtLM

QoS Evaluator
The QoS Evaluator component is responsible for managing and evaluating Service Level Objectives(SLOs) and notifying third parties when any of them is not fulfilled.
Factsheet
Code
Apache License 2.0

Network Policy Support at Kuryr
By default, all Kubernetes pods accept traffic from any source. Network Policy defines how groups of pods are allowed to communicate with each other and other network endpoints. It also suggests a design for supporting Kubernetes “Network policy” in Kuryr
Factsheet
Code
Apache License 2.0

Kuryr integration into Cluster Network Operator
Provides easy deployment and management of KuryrSDN on OpenShift 4.X cluster on top of OpenStack Virtual Machines.
Factsheet
Code
Apache License 2.0

Information Driven Networking
This component provides a set of network methods and software technologies over containers and virtual machines for the enforcement of targeted policies according to the data, security requirements and application needs.
Factsheet
Code
Apache License 2.0

Dynamic Orchestrator
The Dynamic Orchestrator triggers the redeployment of applications during runtime to ensure they comply with their Service Level Objectives (SLOs). It uses a Reinforced Learning-based approach which can operate efficiently, with a light overhead for the s
Factsheet
Code
GPL-Compatible

Kuryr integration into OpenShift
Kuryr Cluster Network Operator component ensures easy deployment and management of KuryrSDN on OpenShift 4.X cluster on top of OpenStack Virtual Machines
Factsheet
Code
Apache License 2.0

Triple Monitoring Engine
The triple monitoring engine provides API and methods for gathering metrics from different sources (infrastructure, data operation, application), those measurements will be stored then expose for being consumed through REST-API and pub/sub.
Factsheet
Code
Apache License 2.0
Data as a Service

Seamless
The Seamless component permits to aggregate the LeanXcale DataBase and an Object Store into a single logical component.
Factsheet
Code
Apache License 2.0

Data Quality Assessment
The Data Quality Assessment component is a domain-agnostic data assessment and an improvement framework, that can identify valid records in a relational database and establish data veracity.
Factsheet
Code
LGPL

Complex Event Processing
The Complex Event Processing (CEP) is in charge of processing flows of data on the fly without storing the data.
Factsheet
Code

Adaptable Distributed Storage
The Adaptable Distribution Storage Component allows the data storage layer to be adapted to diverse workloads. The component allows the LXS datastore to scale effectively during runtime, ensuring transactional semantics and elastic storage.
Factsheet
Code
MIT

Process modelling and optimisation framework for business analysts

Process Modelling Framework
The Process Modelling Tool provides an interface to business users to model their business processes and workflows.
Factsheet
Code
MIT
Data Toolkit

Process Mapping
The Process Mapping component provides an automatic algorithm selection for Meta Learning (ML) tasks. The component follows an ML approach, thus it improves its performance as it is applied on increasing amounts of datasets. Reduces time and effort on fin
Factsheet
Code
GPL v3 License

Data Toolkit
The Data Toolkit is the component which takes care to design an end-to-end Big Data application graph and create a common serialization format in order that it is feasible to execute valid analytics pipelines.
Factsheet
Code
MIT
Application Dimensioning Workbench

Dimensioning Workbench
The Dimensioning Workbench will benchmark the target service via easily configured and automated parameter sweep tests and gather the necessary performance data, train prediction models that are able to regress for cases that have not been met before
Factsheet
Code
Apache License 2.0
Data Visualisation

Data Visualisation
The Data Visualisation Component provides adaptable visualization to support the data analytics for the applications deployed in BigDataStack.
Factsheet
Code
Apache License 2.0
