A holistic solution to the (big) data flow problem

BigDataStack aims to deliver a complete stack including an infrastructure management solution that drives decisions according to live and historical data, thus being fully scalable, runtime adaptable and highly performant. The overall objective is for BigDataStack to address the emerging needs of significant data operations and data-intensive applications. The solution will base all infrastructure management decisions on data aspects (for example the estimation and provision of resources for each data service based on the corresponding data loads), monitoring data from deployments and logic derived from data operations that govern and affect storage, compute and network resources. On top of the infrastructure management solution, “Data as a Service” will be offered to data providers, decision-makers, private and public organisations. Approaches for data quality assessment, data skipping, and efficient storage, combined with seamless data analytics, will be realised holistically across multiple data stores and locations.
Our public
The BigDataStack solution is intended to ease the working life of managers, developers and data scientists in their decision-making processes. Currently, the platform has been tuned and tested on the needs of 3 specific industrial sectors, shipping, retail and insurance but it’s domain agnostic and it can easily fit to virtually any business.
We have identified 3 major players in the dataflow analysis, with very specific roles:
Business Analyst
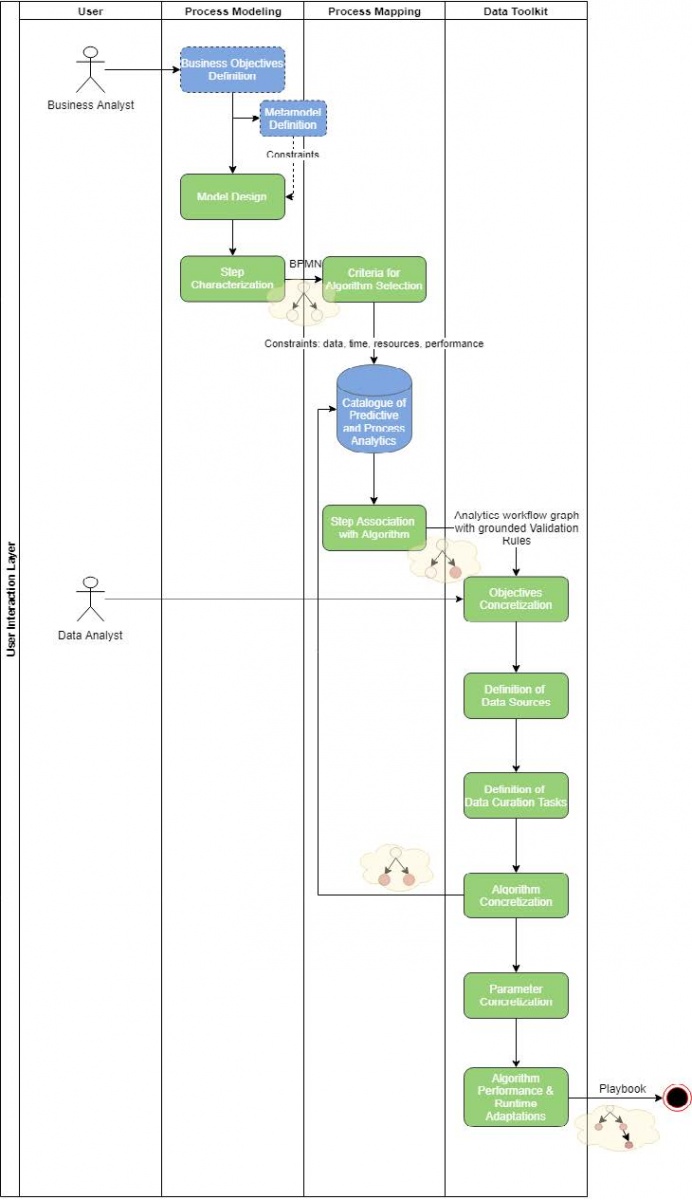
He’s responsible for defining the business processes through specific objectives. The Process Modelling Framework allows him to design the whole data flow via a graphical interface (a Business Process Modeling Notation). The output of this process is a graph-like output with a high-level description of the workflow from the business analyst’s perspective along with the related end-to-end business objectives. The Process Mapping will, therefore, interpret, map and convert the information in the graph into algorithms.
Data Analyst
he will finalise the set up of the data flow in few more steps:
- Setting lower resources if the selected algorithms perform sufficiently well.
- Defining the data sources from where the datasets will be ingested.
- Defining any data curation tasks necessary for the algorithms.
- Tweaking or design new algorithms and analysis tasks, which are then stored to the Catalogue of Predictive and Process Analytics (can be re-used in the future).
- Selecting performance metrics to evaluate the algorithm/model and resources configurations.
Application owner
BigDataStack offers the Application Dimensioning Workbench to enable application owners and engineers to experiment with their application and obtain dimensioning outcomes regarding the required resources for specific data needs and data-related properties
The full architecture
This document provides the final version of the BigDataStack architecture following the previous releases describing our “Conceptual model and Reference architecture” (namely D2.4 and D2.5). It captures the final version of the overall conceptual architecture in terms of information flows and capabilities provided by each one of the main building blocks. This report serves as design documentation for the individual components of the architecture. It presents the outcomes (in terms of design) of the final integrated prototypes and the obtained experimentation and validation results.
Key outcomes
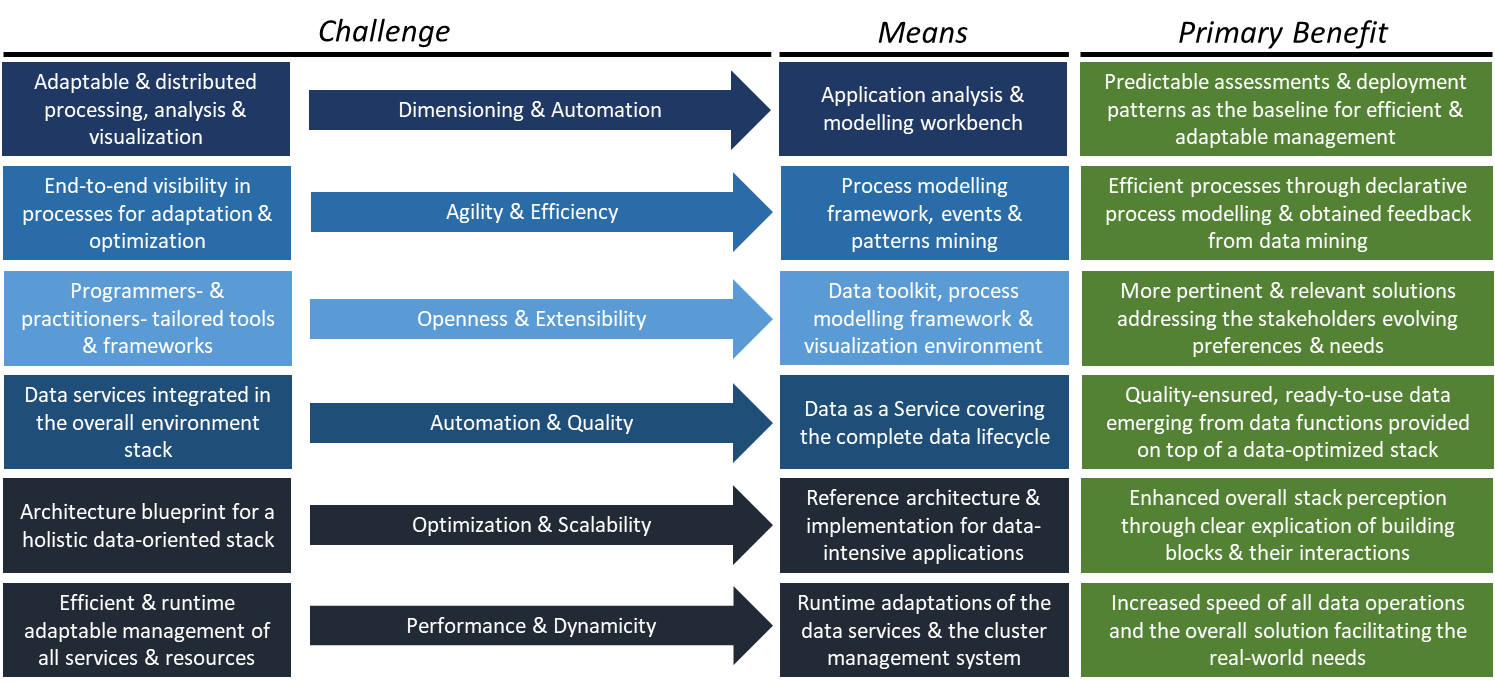
The key outcomes of BigDataStack are reflected in a set of primary building blocks in the corresponding overall architecture of the stack. This report reflects the final version of the critical functionalities of the overall architecture, the interactions between the main building blocks and their components.
Based on the overall architecture presented, the main component listed in this document are:
- Resources Management - Container-based and Virtual Machine-based application management on cloud and on-premise infrastructures
- Data-Driven Network Management - optimisation and management for computing, storage and networking resources.
- Dynamic Orchestrator - redeployment of applications during runtime to ensure they comply with their Service Level Objectives (SLOs)
- Triple Monitoring and QoS Evaluation - API and methods for gathering metrics from different sources, evaluation of SLOs
- Applications & Data Services/ Realization Engine - converting meta code application (user-defined) into actual running deployment and their management.
- Data Quality Assessment - set of algorithms to enable domain-agnostic error detection
- Real-Time Complex Events Processing (CEP) - real-time analysis of data collected from heterogeneous data sources at high rates
- Process Mapping & Analytics - predict and apply the best algorithm from a set
- Seamless Analytics Framework - analysis of dataset stored in one or more underlying physical data stores
- Application Dimensioning Workbench - provide insights regarding the required infrastructure resources for the data services components, linking the used resources with load and expected QoS levels.
- Big Data Layout and Data Skipping - avoid unnecessary data from Object Storage and sending them across the network
- Process Modelling Framework - provides an interface to business users to model their processes and workflows and obtain recommendations for their optimization
- Data Toolkit - design and support data analysis workflows
- Adaptable Visualization - integrate data from several components and display them in a visualisation dashboard
- Adaptable Distributed Storage - dynamic data load balancing, requesting resources from the infrastructure to accomplish the process needs
It should be noted that further design details and evaluation results for all components of the architecture will be delivered in the corresponding follow-up deliverables addressing the user interaction block, the data as a service block and the infrastructure management block.
Number:
D2.60
